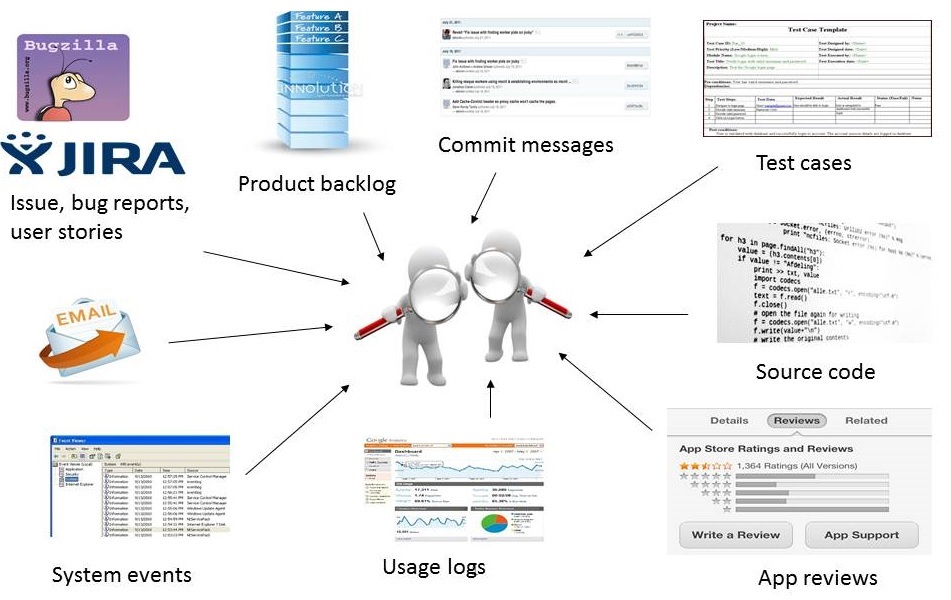
The pervasiveness of software products in all areas of society has resulted in millions of software projects (e.g. over 17 million active projects on GitHub) and a massive amount of data about their development, operation and maintenance (e.g. the well-known Web browser, Mozilla Firefox project, currently has over 300 releases and 1.5 million issues reports since its initial release in 2002). This huge amount of software engineering data is continuously generated at a rapid rate in many forms such as user stories, use cases, requirements specifications, issue and bug reports, source code, test cases, execution logs, app reviews, user and develop mailing lists, discussion threads, and so on. Hidden in those Big Data are insights valuable to project managers, software engineers and other stakeholders about the quality of the development process and the software product, and the experience that software users receive.
Using cutting-edge machine learning and data mining techniques, our Software Engineering Analytics (SEA) research team aims to develop analytics technologies which specifically turn software engineering data into actionable insight. We believe that SEA will significantly improve the theory and practice of software engineering, enabling us to build better software and build software better, addressing both quality and productivity needs.
The SEA research program, led by Dr Hoa Khanh Dam, is part of UOW's Decision System Lab.
News
- Dr Hoa Dam has been invited to visit and give a talk on SEA@UOW research at Faculty of Information Technology, Monash University in April, 2018 - check this link for details
- We will have 2 contributions at ICSE2018: one paper at ICSE NIER and the other at ICSE poster track.
- Dr Hoa Dam has been invited to serve as Program Co-Chair for the 25th Australasian Software Engineering Conference (ASWEC 2018)
- Paper on deep learning for story point estimation in agile development has been accepted to IEEE Transactions on Software Engineering.
- Welcome Aziz (PhD student) and Jack (Honours student) to the SEA@UOW team!
- One PhD scholarship is available for commencing in 2018.
- TSE paper invited for a Journal-First paper presentation at ESEC/FSE 2017
- UOW News: "Critical error: when machines go off-script"